 Fear not, I am not going to perform any analysis proving the intellectual superiority of any race or gender. Also, as a 100% Spaniard (I need to check on that though) I do not belong to the “elite” of ethnics groups disputing supremacy, namely: Northern Europeans, Jews and Far-East Asians and, quite frankly, I feel kinda good about it since I’d rather stick to the Latin Lover stereotype which, by all means, it is true.
Fear not, I am not going to perform any analysis proving the intellectual superiority of any race or gender. Also, as a 100% Spaniard (I need to check on that though) I do not belong to the “elite” of ethnics groups disputing supremacy, namely: Northern Europeans, Jews and Far-East Asians and, quite frankly, I feel kinda good about it since I’d rather stick to the Latin Lover stereotype which, by all means, it is true.
Recently I came across a video titled Steven Pinker – Jews, Genes and Intelligence. Typically I would have disregarded this video as your standard white supremacy internet rhetoric however, I know Steven Pinker from his published works and achievements, and he is no small fish in the Psychology and Cognitive Science world. That is why I decided to give a shot to his video to see what’s what until he began talking about statistics. These are his words:
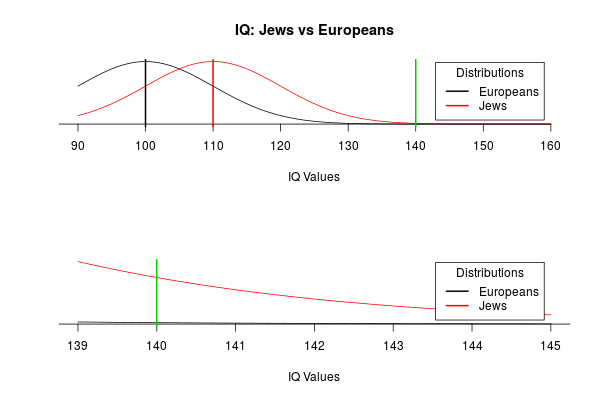
“…Jewish achievements might have an explanation on another fact that has long been known; that Jewish score on average higher on IQ tests than any ethnic group for what there’s comparable data. Their mean IQ is between 108 and 115, the mean of the European population is by definition a hundred which means that the Jewish average is a whole standard deviation higher than the [European] average… Importantly, even if the effect is moderate on average it’s a mathematical fact in Normal Distributions, that is Bell’s Curves, that small effects in the average can translate into huge effects at the extreme… So with one standard deviation difference between groups a score that is three standard deviation above the mean in the higher distribution is four standard deviations in the lower distribution which means there are 42 times as many people at that cut off.” – Steven Pinker
In short, according to Steven Pinker there are 42 times more chances for a Jewish baby to be born an IQ genius than for an European one… But, is that really so?

 Not that I know anything about the GOP debates or candidates, but I casually saw in a CNN post this nice visualization of verbal attacks during the RL GOP Debate, and I thought that I would do a little SNA and try to draw conclusions on the debate WITHOUT actually having seen it…
Not that I know anything about the GOP debates or candidates, but I casually saw in a CNN post this nice visualization of verbal attacks during the RL GOP Debate, and I thought that I would do a little SNA and try to draw conclusions on the debate WITHOUT actually having seen it… 
